

昨日はGPT-3をOpenAIのPlaygroundを使って試してみました。

今日は、OpenAIのAPIを使って、GPT-3を試してみようと思います。
APIには大きく分けて4種類あります。下記のとおりです。
- 完了
Completion - 検索
search - 分類
Classification - 回答
Answer
完了は、Playgroundの最初に試したように文章の続きを生成するもので、GPT-3の自然言語生成の最も基本的なタスクです。
検索は、API実行時か事前にセットしておいたドキュメントと、クエリ文字列のマッチ率を戻すタスクです。マッチ率の高い順にドキュメントを並べれば、検索結果として用いることができるでしょう。
分類は、API実行時か事前にセットしておいたドキュメントと分類ラベルを教師データとして、クエリ文字列にラベル付けを行うタスクです。IBM WatsonでいえばNLC(Natural Language Classifier)やWatson AssistantのIntentのような機能といえます。
回答は、チャットボットにおけるAIからの回答を生成するものです。今日はこの、回答APIについて詳しく見ていきます。
必要なライブラリのインストール
Pythonを使ってAPIを操作するので、最初にSDKをインストールします。
pip install openai
OpenAIのドキュメントにはAPIの操作サンプルが掲載されています。そこでは、API KEYを環境変数から取得するようになっているので、今回は.envファイルで環境変数の値をセットするようにします。そのため、python-dotenvもインストールしておきます。
pip install python-dotenv
API KEYの設定
API KEYは、OpenAIにログインしてAPI Keysの画面で取得できます。
今回はJupyter Notebook環境でPythonを実行するので、そのipynbファイルと同じディレクトリなどに.envファイルを作成し、下記のような内容にします。
OPENAI_API_KEY=<API KEY>
Answerサンプルの実行
まずは、OpenAIのドキュメントにあるとおりのサンプルを実行してみます。.envファイルの読み込み処理のみ追加しました。
import os
import openai
from dotenv import load_dotenv # この行を追加
load_dotenv() # この行を追加
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Answer.create(
search_model="ada",
model="curie",
question="which puppy is happy?",
documents=["Puppy A is happy.", "Puppy B is sad."],
examples_context="In 2017, U.S. life expectancy was 78.6 years.",
examples=[["What is human life expectancy in the United States?","78 years."]],
max_tokens=5,
stop=["\n", "<|endoftext|>"],
)
実行結果は下記のようなものでした。
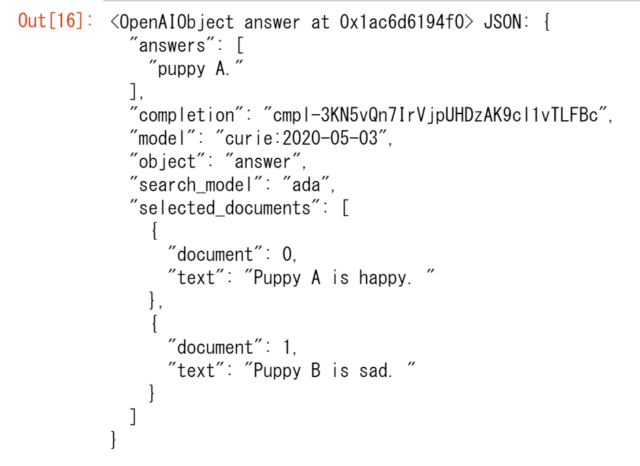
リクエストのパラメータで、documentsの値を["Puppy A is happy.", "Puppy B is sad."]のようにセットしています。これがAIに与える知識のようなものです。このdocumentsの値は200件を超える場合は別にファイルで渡すことになります。
questionはチャットにおける人間の発言(質問)に相当し、"which puppy is happy?"という文字列を与えています。ハッピーなのはAの方ですね。
ちょっと分かりづらいのは、example_contextとexamplesでしょう。上記のquestionは、documentsの値に基づけば、Aだと回答すれば良いのですが、単なる検索ではなくチャットボットなので、どのようなトーンの言葉で返せば良いのかが分かりません。ぶっきらぼうに「A」と言えば良いのか、「それはAです」のように答えるのか、はたまた「Aがハッピーなようです」のようにするのか。そうした回答のトーンを決定するのが、example_contextとexamplesの役割です。examplesは質問と回答が対になったリストを複数含む(1つでも良い)リストになっていて、今回は"78 years."のようにぶっきらぼうに回答しているわけですね。また、質問"What is human life expectancy in the United States?"に対する知識はexample_contextによって得られます。
日本語でやってみる
サンプルの実行内容がだいたい分かったところで、日本語で試してみます。
import json
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Answer.create(
search_model="ada",
model="curie",
question="三郎は何をもらうと嬉しいですか",
documents=["太郎はコーヒーが好き", "二郎はお酒が好き", "三郎はココアが好き", "花子はお酒が好き"],
examples_context="ビビンコは2018年に設立された",
examples=[["ビビンコはいつ設立された?", "2018年"]],
max_tokens=100,
stop=["\n", "<|endoftext|>"],
)
print(json.dumps(response, ensure_ascii=False, indent=2))

回答は「ココア」でした。たしかに三郎はココアが好きなので、正しい回答ですね。また、examplesを見るとぶっきらぼうな回答をしているので、それも踏襲しています。
response = openai.Answer.create(
search_model="ada",
model="curie",
question="三郎は何をもらうと嬉しいですか",
documents=["太郎はコーヒーが好き", "二郎はお酒が好き", "三郎はココアが好き", "花子はお酒が好き"],
examples_context="ビビンコは2018年に設立された",
examples=[["ビビンコはいつ設立された?", "それは2018年です。"]],
max_tokens=100,
stop=["\n", "<|endoftext|>"],
)
print(json.dumps(response, ensure_ascii=False, indent=2))
examplesを少し変えてみました。

回答が一気に丁寧になりました。これでexamplesの使い方が分かったと思います。
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Answer.create(
search_model="ada",
model="curie",
question="三郎は何が嫌いですか",
documents=["太郎はコーヒーが好き", "二郎はお酒が好き", "三郎はココアが好き", "花子はお酒が好き"],
examples_context="ビビンコは2018年に設立された",
examples=[["ビビンコはいつ設立された?", "それは2018年です。"]],
max_tokens=100,
stop=["\n", "<|endoftext|>"],
)
print(json.dumps(response, ensure_ascii=False, indent=2))
ちょっと意地悪な質問です。三郎が嫌いなものは知識として与えていません。どんな回答になるでしょうか。

なるほど。たしかに三郎はココアが好きなので、この回答はやむを得ないですね。
といった感じで、Answerについてどのような動きをするのか試してみました。